学习目标:
- 理解 Redis 的定位、特点与典型应用场景
- 掌握 String、List、Set、Hash、Sorted Set 等常用数据结构
- 熟悉持久化、内存淘汰策略与常见缓存问题
- 能在 Java / Spring Boot 中完成 Redis 基础整合与使用
- 能用 Redis 解决缓存、计数器、排行榜等常见问题
本章重点:
- Redis 与关系型数据库的差异
- 五大核心数据结构与适用场景
- RDB / AOF 持久化与内存淘汰策略
- 缓存穿透、击穿、雪崩三大问题的处理思路
1. 引言
1.1 Web发展历程
迄今为止,互联网的发展已经经历了两个阶段:Web 1.0 和 Web 2.0。
| 阶段 | 特点 | 代表 |
|---|---|---|
| Web 1.0 | 静态网站,单方面信息传递,无互动 | 搜狐、新浪、网易 |
| Web 2.0 | 内容互动,用户成为内容提供方 | 微博、B站、抖音 |
1.2 传统关系型数据库的挑战
进入 Web 2.0 时代后,数据爆炸式增长,传统关系型数据库面临以下挑战:
High Performance - 高并发写需求
Web 2.0 网站需要根据用户个性化信息实时生成动态页面,数据库并发负载极高(每秒上万次读写请求)。关系型数据库难以承受如此高的硬盘 IO 压力。
Huge Storage - 海量数据存储
大型 SNS 网站每天产生海量用户动态。以 FriendFeed 为例,一个月就产生 2.5 亿条动态。在单表 2.5 亿条记录中进行 SQL 查询,效率极其低下。
1.3 NoSQL的诞生
Web 2.0 应用中,关系型数据库的许多特性反而成为负担:
- 很多实时系统不要求严格的事务
- 对读写一致性要求较低
- 避免多表关联查询,多为单表主键查询
因此,NoSQL 数据库应运而生。
Redis 是典型的 NoSQL 数据库,与传统关系型数据库相比:
- 纯内存存储
- Key-Value 键值对结构
- 非结构化数据
2. Redis简介
2.1 什么是Redis
Redis(Remote Dictionary Server)是一个使用 C 语言编写的、开源的、支持网络的、基于内存的、可持久化的 Key-Value 非关系型数据库。
2.2 Redis核心特点
| 特性 | 说明 |
|---|---|
| C语言编写 | 性能极高,单机可达 10万+ QPS |
| 开源免费 | GitHub: https://github.com/redis |
| 基于内存 | 数据存储在内存中,读写速度极快 |
| 可持久化 | 支持 RDB 和 AOF 两种持久化方式 |
| Key-Value | 以键值对方式存储数据 |
| 支持网络 | 客户端通过网络连接服务端 |
| 多语言API | 支持 Java、Python、Go、Node.js 等 |
2.3 参考资源
- 中文官网: https://www.redis.net.cn/
- 命令参考: http://doc.redisfans.com/
- 官方文档: https://redis.io/documentation
3. 安装与启动
⚠️ 注意: Redis 官方不支持 Windows 操作系统,但 Windows 团队提供了适配版本。
3.1 Windows安装
下载
从 GitHub 下载 Windows 适配版本:
- 地址: https://github.com/microsoftarchive/redis/releases

解压
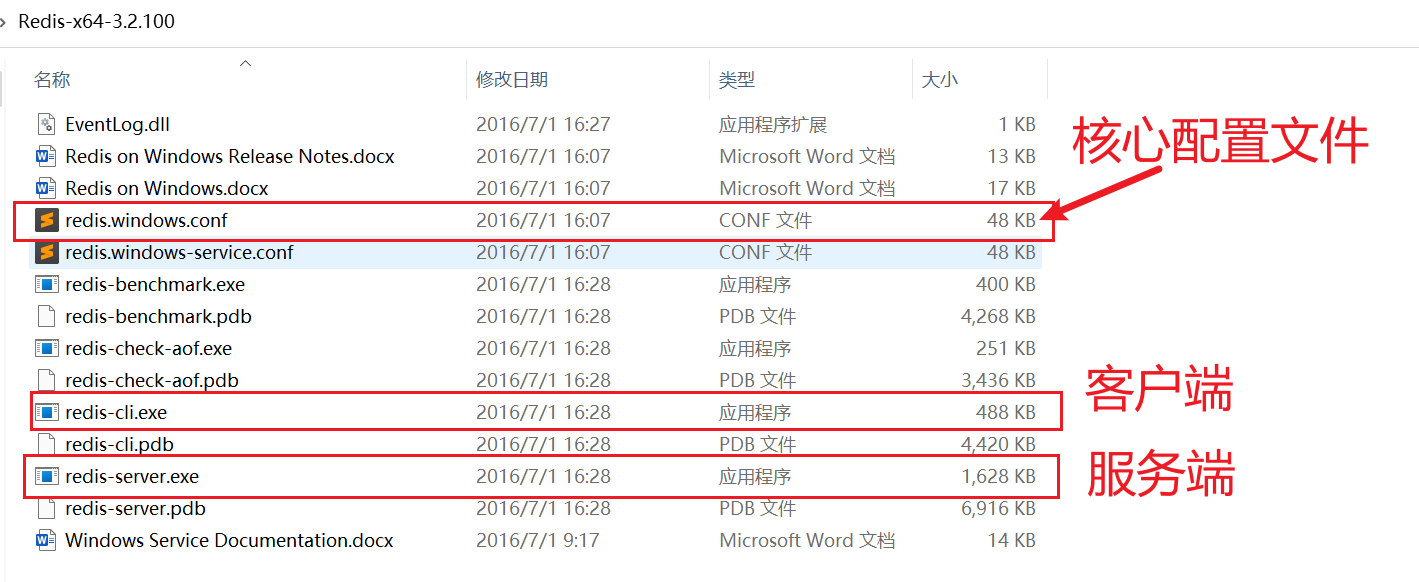
解压后目录结构:
redis/
├── redis-server.exe # 服务端程序
├── redis-cli.exe # 客户端程序
├── redis.windows.conf # 配置文件
└── ...
启动服务端
# 方式1: 使用默认配置
redis-server.exe
# 方式2: 指定配置文件(推荐)
redis-server.exe redis.windows.conf启动成功后会看到如下输出:
[*****] # Server initialized
[*****] * Ready to accept connections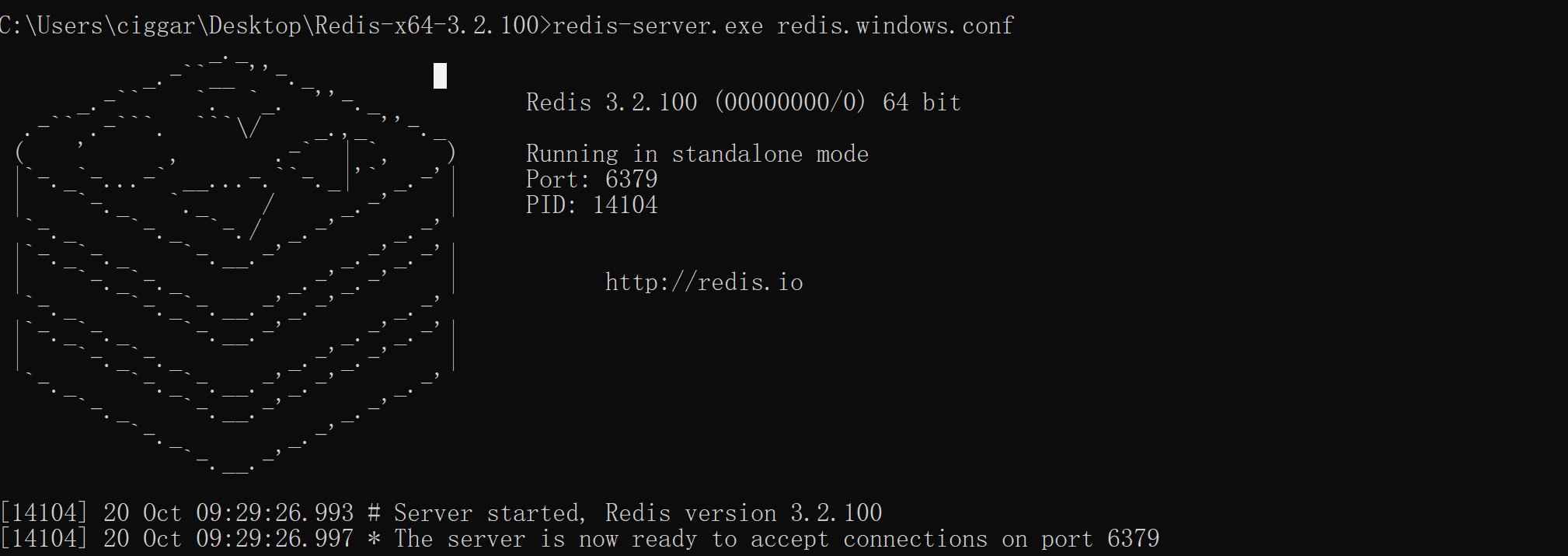
启动客户端
# 连接本地默认端口
redis-cli.exe
# 连接指定主机和端口
redis-cli.exe -h localhost -p 6379
# 连接带密码的Redis
redis-cli.exe -h localhost -p 6379 -a password3.2 Docker安装
如果本机已经安装了 Docker,那么使用容器启动 Redis 会更快捷
# 拉取官方镜像
docker pull redis:7.2-alpine
# 启动 Redis 容器
docker run -d \
--name redis-demo \
-p 6379:6379 \
-v /docker/redis-data:/data \
redis:7.2-alpine \
redis-server --appendonly yes
# 查看容器状态
docker ps
# 进入 Redis 命令行
docker exec -it redis-demo redis-cli
# 测试连接
PING常用管理命令:
# 停止容器
docker stop redis-demo
# 启动已存在的容器
docker start redis-demo
# 删除容器(删除前先停止)
docker rm -f redis-demo3.3 图形化客户端
除了命令行客户端 redis-cli,我们也可以使用图形化工具来连接 Redis,查看 key、修改数据和观察数据结构。
一个常见选择是 Another Redis Desktop Manager。
在学习阶段,图形化客户端比较适合做这些事:
- 直观看 Redis 中有哪些 key
- 查看 String、Hash、List、Set、Sorted Set 的实际存储效果
- 辅助验证命令执行结果
💡 建议:
- 初学命令时优先使用
redis-cli- 观察数据结构和排查数据时,再配合图形化客户端一起使用
- 图形化工具方便,但不要因此忽略 Redis 命令本身
4. 核心配置
4.1 常规配置
编辑 redis.conf 或 redis.windows.conf:
# 是否以守护进程方式运行(Linux)
daemonize no
# 客户端超时时间(0表示不超时)
timeout 0
# 端口号(默认6379)
port 6379
# 绑定地址
bind 127.0.0.1
# bind 0.0.0.0 # 允许所有IP连接(生产环境慎用)
# 日志级别: debug | verbose | notice | warning
loglevel notice
# 数据库数量(默认16个)
databases 16
# 设置密码
requirepass your_password4.2 持久化配置
RDB(Redis Database)
RDB 通过内存快照的方式持久化数据,是 Redis 默认的持久化策略。
配置示例:
# 快照保存目录
dir /var/lib/redis
# 快照文件名
dbfilename dump.rdb
# 触发策略: save <秒> <变化次数>
save 900 1 # 900秒内至少1次修改
save 300 10 # 300秒内至少10次修改
save 60 10000 # 60秒内至少10000次修改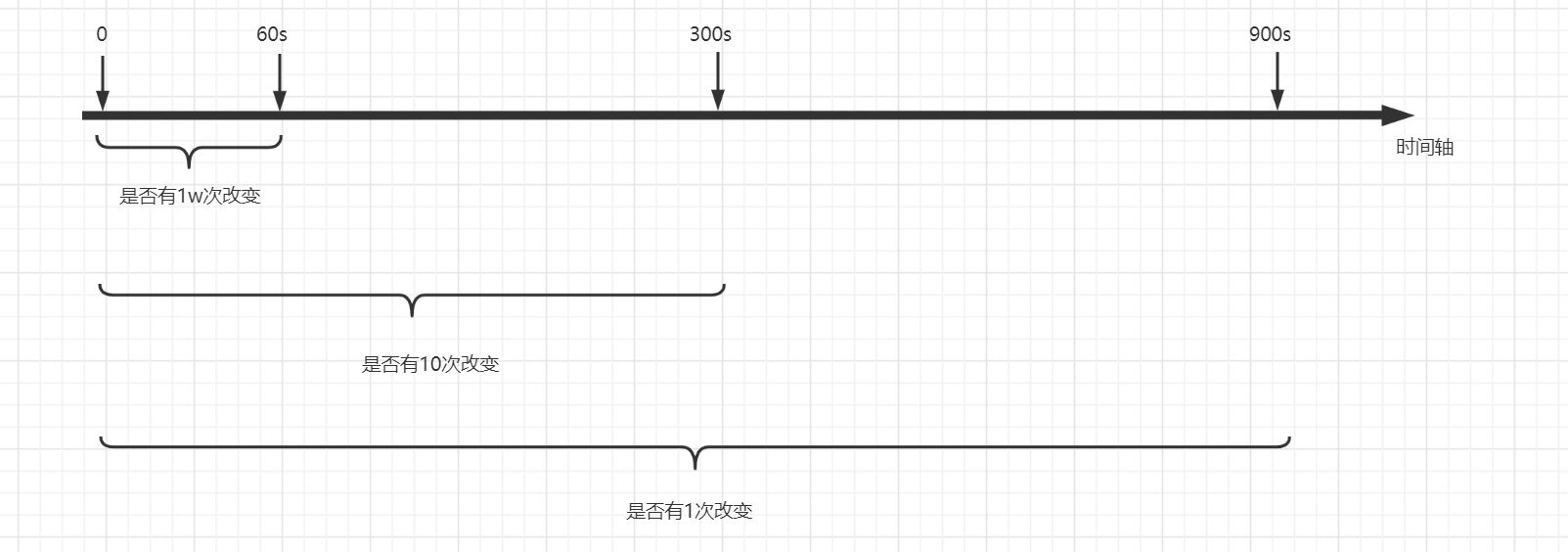
RDB特点:
- ✅ 保存速度快,文件体积小
- ✅ 恢复速度快
- ❌ 可能丢失最后一次快照后的数据
💡 可以这样理解 RDB:
- RDB 像是给某一个时刻的内存状态拍了一张完整快照
- 每次保存的是当时的全量数据,不是增量日志
- 因为保存的是快照,所以备份和恢复都比较快
- 但如果 Redis 在下一次快照前宕机,就可能丢失这段时间的新数据
AOF(Append Only File)
AOF 通过追加写入命令的方式持久化数据。
配置示例:
# 开启AOF
appendonly yes
# AOF文件路径(与RDB共用dir配置)
dir /var/lib/redis
# AOF文件名
appendfilename "appendonly.aof"
# 同步策略
# appendfsync always # 每条命令都同步(最安全,最慢)
appendfsync everysec # 每秒同步(推荐)
# appendfsync no # 由操作系统决定AOF特点:
- ✅ 数据安全性高(可做到不丢数据)
- ❌ 文件体积大
- ❌ 恢复速度慢(需重放命令)
💡 可以这样理解 AOF:
- AOF 不保存某一刻的完整状态,而是把写命令持续追加到日志文件里
- 恢复数据时,本质上就是把这些写命令重新执行一遍
- 因为记录得更细,所以数据安全性通常比 RDB 更高
- 但文件会更大,恢复也会更慢一些
💡 最佳实践:
- 生产环境建议同时开启 RDB 和 AOF
- 两者同时开启时,Redis 恢复数据通常优先使用 AOF
- 课堂理解上可以记成一句话:
RDB 更像快照,AOF 更像操作日志
5. 数据结构
在正式学习 Redis 数据结构之前,先记住一个最核心的认识:
Redis 存储的本质是键值对,也就是 key -> value。
这里说的“数据结构”,多数时候主要指的是 value 的结构,比如:
- value 是一个普通字符串,对应
String - value 是一个列表,对应
List - value 是一个集合,对应
Set - value 是一个键值对集合,对应
Hash - value 是一个带分数的有序集合,对应
Sorted Set
而 key 本身通常只是一个字符串,但在实际开发中,我们会把它设计得更有层次,常见写法是用冒号 : 分隔多级含义。
例如:
user:1001:name
user:1001:cart
order:20240501:10001
article:1001:view这种命名方式的好处是:
- 语义清晰,看到 key 基本就知道它表示什么数据
- 方便按前缀查询,例如
KEYS user:* - 便于团队统一命名规范,减少后期维护成本
5.1 通用命令
# 切换数据库(0-15,默认0)
SELECT index
# 密码认证
AUTH password
# 查找key(支持通配符: * ? [])
KEYS pattern
KEYS * # 查看所有key
KEYS user:* # 查看前缀为user:的key
# 清空所有数据库(危险操作!)
FLUSHALL
# 清空当前数据库
FLUSHDB
# 删除key
DEL key
# 查看key类型
TYPE key
# 设置key过期时间(秒)
EXPIRE key seconds
# 查看key剩余生存时间
TTL key5.2 String(字符串)
最基础的数据类型,可存储字符串、数字。

基本命令
# 设置key-value(key存在则覆盖)
SET key value
# 获取value
GET key
# 批量设置
MSET key1 value1 key2 value2 ...
# 批量获取
MGET key1 key2 ...
# 数值+1
INCR key
# 数值+指定步长
INCRBY key increment
# 数值-1
DECR key
# 数值-指定步长
DECRBY key decrement
# 设置key并指定过期时间(秒)
SETEX key seconds value
# 仅当key不存在时才设置
SETNX key value应用场景
| 场景 | 实现方式 | 指令说明 |
|---|---|---|
| 缓存 | SET user:1001 "{...}" + EXPIRE |
先写入缓存数据,再设置过期时间 |
| 计数器 | INCR page:view:homepage |
对访问次数做原子自增 |
| 限流 | INCR user:1001:api:count + EXPIRE 60 |
在固定时间窗口内统计请求次数 |
5.3 List(列表)
双向链表实现,支持两端插入/弹出。
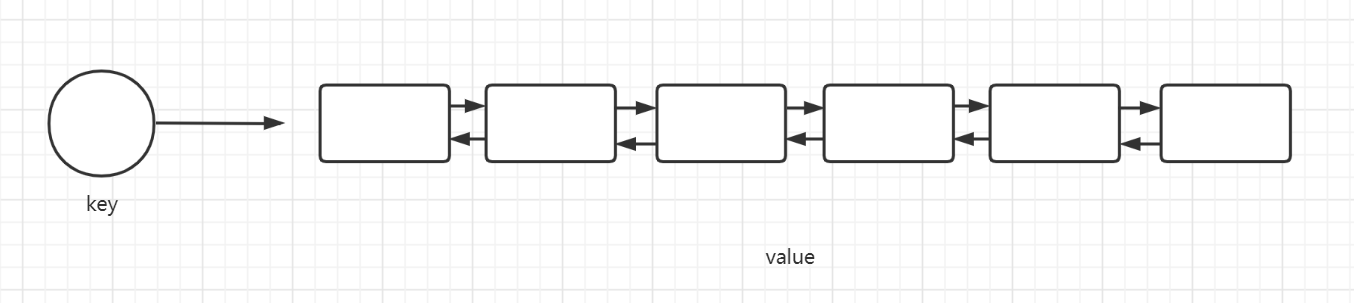
基本命令
# 从左侧插入
LPUSH key value1 value2 ...
# 从左侧弹出
LPOP key
# 从右侧插入
RPUSH key value1 value2 ...
# 从右侧弹出
RPOP key
# 获取列表长度
LLEN key
# 获取指定范围元素(0表示第一个,-1表示最后一个)
LRANGE key start stop
# 获取指定索引元素
LINDEX key index
# 在指定元素前/后插入
LINSERT key BEFORE|AFTER pivot value
# 修改指定索引元素
LSET key index value
# 删除指定元素(count>0从头删,count<0从尾删,count=0全删)
LREM key count value应用场景
| 场景 | 实现方式 | 指令说明 |
|---|---|---|
| 消息队列 | LPUSH + BRPOP(阻塞弹出) |
一端写入消息,另一端阻塞等待并消费消息 |
| 最新动态 | LPUSH timeline:user:1001 "..." + LTRIM 0 99 |
头部插入最新内容,并只保留最近100条 |
| 栈 | LPUSH + LPOP |
同一端进出,后进先出 |
| 队列 | LPUSH + RPOP |
一端进入另一端取出,先进先出 |
5.4 Set(集合)
无序、不重复的字符串集合。
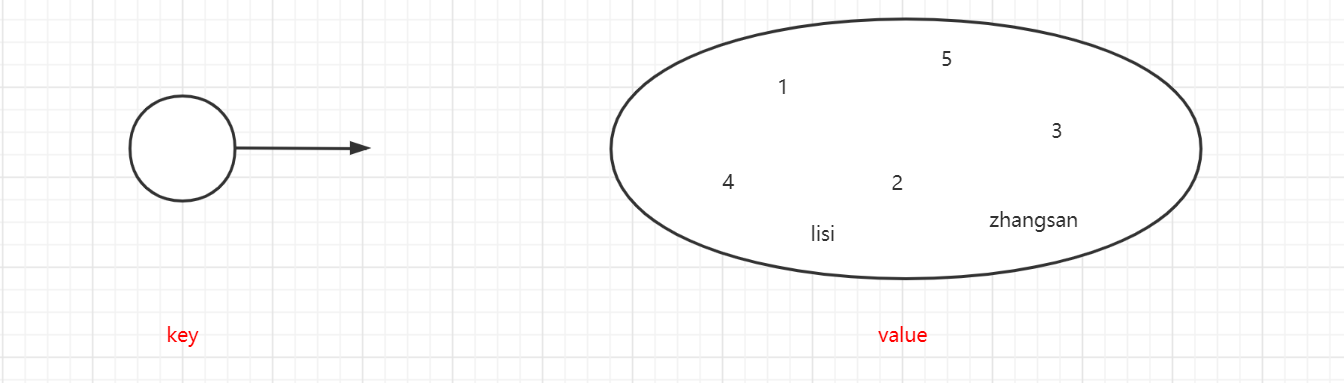
基本命令
# 添加成员
SADD key member1 member2 ...
# 获取成员数量
SCARD key
# 获取所有成员
SMEMBERS key
# 判断成员是否存在
SISMEMBER key member
# 随机弹出指定数量成员
SPOP key [count]
# 随机获取指定数量成员(不删除)
SRANDMEMBER key [count]
# 求交集
SINTER key1 key2 ...
# 求交集并保存
SINTERSTORE destination key1 key2 ...
# 求并集
SUNION key1 key2 ...
# 求并集并保存
SUNIONSTORE destination key1 key2 ...
# 求差集
SDIFF key1 key2 ...
# 求差集并保存
SDIFFSTORE destination key1 key2 ...
# 移动成员到另一个集合
SMOVE source destination member
# 删除成员
SREM key member1 member2 ...应用场景
| 场景 | 实现方式 | 指令说明 |
|---|---|---|
| 共同好友 | SINTER user:1001:friends user:1002:friends |
求两个好友集合的交集 |
| 好友推荐 | SDIFF user:1001:friends user:1002:friends |
求差集,找出只在一方集合中的成员 |
| 标签系统 | SADD article:1001:tags "java" "redis" |
给文章绑定多个不重复标签 |
| 抽奖 | SRANDMEMBER prize:pool 3 |
随机取出若干奖池成员 |
| 去重 | SADD ip:2024-01-01 "192.168.1.1" |
利用集合成员唯一性做去重 |
5.5 Hash(哈希)
键值对集合,适合存储对象。
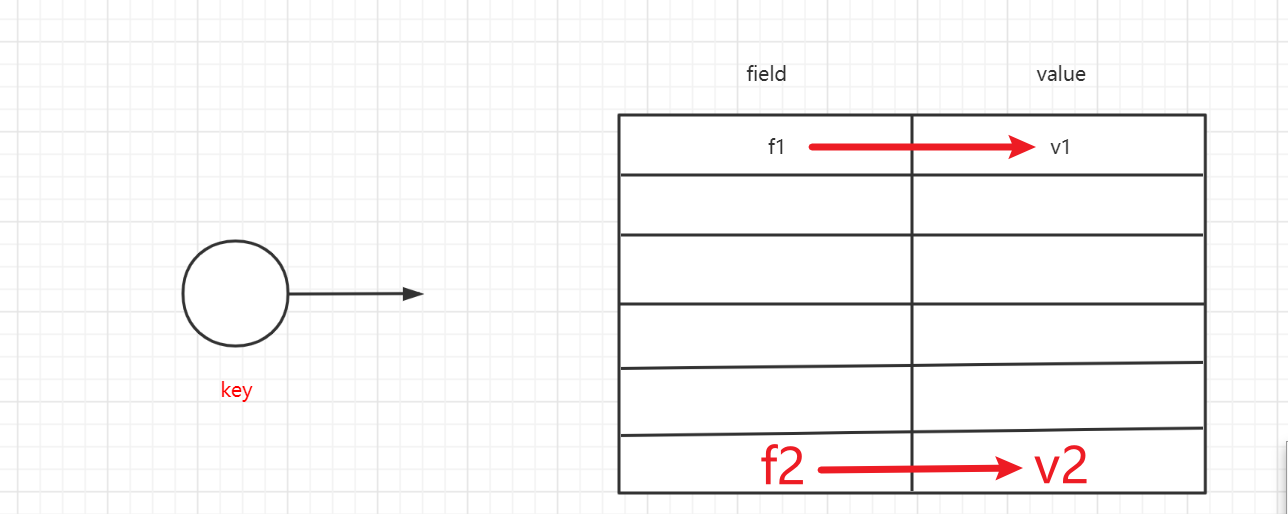
基本命令
# 设置字段
HSET key field value
# 获取字段值
HGET key field
# 批量设置
HMSET key field1 value1 field2 value2 ...
# 批量获取
HMGET key field1 field2 ...
# 判断字段是否存在
HEXISTS key field
# 获取所有字段和值
HGETALL key
# 获取所有字段
HKEYS key
# 获取所有值
HVALS key
# 获取字段数量
HLEN key
# 字段值增加指定数值
HINCRBY key field increment
# 仅当字段不存在时才设置
HSETNX key field value
# 删除字段
HDEL key field1 field2 ...应用场景
| 场景 | 实现方式 | 指令说明 |
|---|---|---|
| 用户信息 | HSET user:1001 name "张三" age 25 |
把同一个对象的多个字段存进一个 hash |
| 购物车 | HSET cart:user:1001 product:10001 2 |
用 field 表示商品,用 value 表示数量 |
| 配置信息 | HSET config:app version "1.0.0" env "prod" |
将一组相关配置集中存储在同一个 hash 中 |
5.6 Sorted Set(有序集合)
每个成员关联一个分数,按分数排序。
基本命令
# 添加成员(分数在前)
ZADD key score1 member1 score2 member2 ...
# 获取成员数量
ZCARD key
# 获取指定分数区间成员数量
ZCOUNT key min max
# 获取成员分数
ZSCORE key member
# 增加成员分数
ZINCRBY key increment member
# 按排名升序获取(0表示第一名)
ZRANGE key start stop [WITHSCORES]
# 按排名降序获取
ZREVRANGE key start stop [WITHSCORES]
# 按分数升序获取
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
# 按分数降序获取
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
# 获取成员升序排名
ZRANK key member
# 获取成员降序排名
ZREVRANK key member
# 删除成员
ZREM key member1 member2 ...
# 删除指定排名区间成员
ZREMRANGEBYRANK key start stop
# 删除指定分数区间成员
ZREMRANGEBYSCORE key min max应用场景
| 场景 | 实现方式 | 指令说明 |
|---|---|---|
| 排行榜 | ZADD leaderboard 100 "player1" |
用分数表示排名依据,成员自动按分数排序 |
| 延时队列 | ZADD delay:queue timestamp "task" |
用时间戳做 score,到时间后再取出任务 |
| 范围查询 | ZRANGEBYSCORE articles 1700000000 1700086400 |
按 score 区间筛选成员 |
| 热度排序 | ZINCRBY hot:articles 1 "article:1001" |
每次访问就给文章热度加分,再按分数排序 |
6. 内存淘汰策略
当内存达到上限时,Redis 会触发淘汰策略删除旧数据。
6.1 淘汰策略分类
volatile 系列(针对设置了过期时间的key)
| 策略 | 说明 |
|---|---|
| volatile-lru | 淘汰最近最少使用的key |
| volatile-lfu | 淘汰一段时间内使用频率最低的key |
| volatile-random | 随机淘汰 |
| volatile-ttl | 淘汰即将过期的key |
allkeys 系列(针对所有key)
| 策略 | 说明 |
|---|---|
| allkeys-lru | 淘汰最近最少使用的key |
| allkeys-lfu | 淘汰一段时间内使用频率最低的key |
| allkeys-random | 随机淘汰 |
其他
| 策略 | 说明 |
|---|---|
| noeviction | 不淘汰,新写入直接报错(默认) |
6.2 配置方法
# 配置最大内存
maxmemory 256mb
# 配置淘汰策略
maxmemory-policy allkeys-lru6.3 策略选择建议
| 场景 | 推荐策略 |
|---|---|
| 缓存场景 | allkeys-lru 或 allkeys-lfu |
| 需要保留热数据 | allkeys-lfu |
| 时效性数据 | volatile-ttl |
| 不允许丢数据 | noeviction |
6.4 适合存储在Redis中的数据特征
- ✅ 访问频率高(QPS大)
- ✅ 对丢失不敏感
- ✅ 数据量相对较小
- ✅ 需要快速读写
7. Java客户端
Redis 和 MySQL 一样,都是典型的 C/S 架构应用。
除了 redis-cli 这样的命令行客户端之外,也有图形化客户端和 Java 客户端。
在 Java 开发里,最常见的客户端选择有:
- Jedis:贴近 Redis 原生命令,课堂中以了解为主
- Lettuce:Spring Boot 默认集成较多,支持异步和响应式
7.1 客户端对比
| 客户端 | 特点 | 推荐场景 |
|---|---|---|
| Jedis | 简单直接,API与Redis命令对应 | 了解原生命令映射 |
7.2 Jedis使用
这一部分以了解为主,重点是知道 Jedis 和 Redis 原生命令的对应关系,不作为本课的主要实战客户端。
Maven依赖(推荐4.x版本)
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.4.3</version>
</dependency>基础使用
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisDemo {
// 单连接(不推荐生产使用)
public void basicUsage() {
Jedis jedis = new Jedis("localhost", 6379);
jedis.auth("password"); // 如果有密码
jedis.set("key", "value");
String value = jedis.get("key");
System.out.println(value);
jedis.close();
}
// 连接池(推荐)
public void poolUsage() {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(100); // 最大连接数
config.setMaxIdle(50); // 最大空闲连接
config.setMinIdle(10); // 最小空闲连接
try (JedisPool pool = new JedisPool(config, "localhost", 6379, 3000, "password");
Jedis jedis = pool.getResource()) {
jedis.set("pool:key", "value");
String value = jedis.get("pool:key");
System.out.println(value);
}
}
}保存对象时的常见做法
Jedis 最适合直接操作字符串、数字和 Redis 原生命令。
如果业务里要保存一个 Java 对象,常见做法通常不是把对象直接丢进去,而是先转成 JSON 字符串再存入 Redis。
import com.fasterxml.jackson.databind.ObjectMapper;
import redis.clients.jedis.Jedis;
public class JedisJsonDemo {
private static final ObjectMapper MAPPER = new ObjectMapper();
public void saveUser() throws Exception {
try (Jedis jedis = new Jedis("localhost", 6379)) {
jedis.auth("password");
User user = new User(1L, "zhangsan", "zhangsan@example.com");
String json = MAPPER.writeValueAsString(user);
jedis.set("user:1", json);
}
}
public User getUser() throws Exception {
try (Jedis jedis = new Jedis("localhost", 6379)) {
jedis.auth("password");
String json = jedis.get("user:1");
return json == null ? null : MAPPER.readValue(json, User.class);
}
}
}这个例子想说明的重点不是 ObjectMapper 本身,而是两件事:
- Jedis 的方法名通常和 Redis 命令一一对应,学习成本低
- 当你要存复杂对象时,
对象 -> JSON -> Redis是非常常见的一条路线
操作各数据类型
public void dataTypeOperations(Jedis jedis) {
// String
jedis.set("user:1:name", "张三");
jedis.expire("user:1:name", 3600);
// Hash
jedis.hset("user:1", "name", "张三");
jedis.hset("user:1", "age", "25");
Map<String, String> user = jedis.hgetAll("user:1");
// List
jedis.lpush("queue:tasks", "task1", "task2");
String task = jedis.rpop("queue:tasks");
// Set
jedis.sadd("tags:article:1", "java", "redis");
Set<String> tags = jedis.smembers("tags:article:1");
// Sorted Set
jedis.zadd("rank:score", 100, "player1");
jedis.zadd("rank:score", 95, "player2");
Set<Tuple> topPlayers = jedis.zrevrangeWithScores("rank:score", 0, 9);
}8. Spring Boot整合Redis
8.1 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>8.2 配置文件
说明:以下示例使用 Spring Boot 3.x 的配置前缀
spring.data.redis.*。
spring:
data:
redis:
host: localhost
port: 6379
password:
database: 0
timeout: 3000ms
lettuce:
pool:
max-active: 8 # 最大连接数
max-idle: 8 # 最大空闲连接
min-idle: 0 # 最小空闲连接
max-wait: 1000ms # 最大等待时间8.3 使用StringRedisTemplate
这一部分是 Spring Boot 整合 Redis 的主线内容,重点掌握日常字符串、哈希、列表、集合和有序集合操作。
@Service
public class RedisService {
@Autowired
private StringRedisTemplate redisTemplate;
// String操作
public void stringOps() {
redisTemplate.opsForValue().set("key", "value");
redisTemplate.opsForValue().set("key", "value", 30, TimeUnit.SECONDS);
String value = redisTemplate.opsForValue().get("key");
}
// Hash操作
public void hashOps() {
redisTemplate.opsForHash().put("user:profile:1", "name", "张三");
redisTemplate.opsForHash().put("user:profile:1", "age", "25");
Map<Object, Object> entries = redisTemplate.opsForHash().entries("user:profile:1");
}
// List操作
public void listOps() {
redisTemplate.opsForList().leftPush("queue", "task1");
String task = redisTemplate.opsForList().rightPop("queue");
}
// Set操作
public void setOps() {
redisTemplate.opsForSet().add("tags", "java", "redis");
Set<String> tags = redisTemplate.opsForSet().members("tags");
}
// Sorted Set操作
public void zsetOps() {
redisTemplate.opsForZSet().add("rank", "player1", 100);
Set<ZSetOperations.TypedTuple<String>> top =
redisTemplate.opsForZSet().reverseRangeWithScores("rank", 0, 9);
}
}8.4 使用RedisTemplate(对象序列化)
💡 课堂定位:这一部分作为补充了解,重点知道当 value 不再是简单字符串时,通常需要考虑序列化方式。
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// 使用JSON序列化,避免 Jackson 版本差异带来的编译问题
StringRedisSerializer stringSerializer = new StringRedisSerializer();
GenericJackson2JsonRedisSerializer jsonSerializer = new GenericJackson2JsonRedisSerializer();
// 设置key和value的序列化方式
template.setKeySerializer(stringSerializer);
template.setValueSerializer(jsonSerializer);
template.setHashKeySerializer(stringSerializer);
template.setHashValueSerializer(jsonSerializer);
template.afterPropertiesSet();
return template;
}
}使用示例
配置好 RedisTemplate<String, Object> 之后,就可以直接把普通 Java 对象作为 value 存入 Redis。
public class User {
private Integer id;
private String name;
private Integer age;
public User() {
}
public User(Integer id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}@Service
public class UserRedisService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public void saveUser() {
User user = new User(1, "张三", 25);
redisTemplate.opsForValue().set("user:object:1", user);
redisTemplate.expire("user:object:1", 30, TimeUnit.MINUTES);
}
public User getUser() {
Object obj = redisTemplate.opsForValue().get("user:object:1");
return obj == null ? null : (User) obj;
}
}@RestController
@RequestMapping("/redis/user")
public class UserRedisController {
@Autowired
private UserRedisService userRedisService;
@GetMapping("/save")
public String saveUser() {
userRedisService.saveUser();
return "保存成功";
}
@GetMapping
public User getUser() {
return userRedisService.getUser();
}
}说明
- 写入时,
User对象会先被序列化成 JSON 再存入 Redis - 读取时,RedisTemplate 会按配置的序列化器把 JSON 反序列化回 Java 对象
- 同一个 key 只能对应一种数据类型,例如
user:profile:1用作 Hash 时,就不要再拿user:profile:1去存普通字符串或对象,否则会报WRONGTYPE Operation against a key holding the wrong kind of value - 如果项目里只是保存简单字符串,优先使用
StringRedisTemplate;只有在需要直接存对象时,再考虑RedisTemplate<String, Object>
9. 附录:数据结构应用场景速查表
| 数据结构 | 主要应用场景 | 关键优势 |
|---|---|---|
| String | 缓存、计数器 | 原子操作、可设置过期 |
| Hash | 对象存储、购物车 | 节省内存、字段独立更新 |
| List | 消息队列、时间线 | 双向操作、阻塞读取 |
| Set | 去重、社交关系 | 天然去重、集合运算 |
| Sorted Set | 排行榜、范围查询 | 自动排序、范围查询 |