问题引出
学习完了注册中心相关知识,在微服务架构中,我们已经可以实现服务的注册与自动发现了。但是再来看看我们的代码
// 1 获取指定服务名称的服务实例列表
List<ServiceInstance> instances = discoveryClient.getInstances("user-service");
// 2 选择服务实例,获取uri(格式为http://服务实例ip:服务实例启动端口)
URI uri = instances.get(0).getUri();
// 3 向用户服务发起服务调用请求(注意,这里没有写死ip地址和端口号了!!!)
String address = template.getForObject(uri.toString() + "/user/address/{userId}", String.class, order.getUserId());服务是可以有集群的,在发现了一个服务所有的实例之后,在一次服务调用过程中,我们还需要选择其中一个服务实例,发起调用请求,所以发起调用之前还存在着一个选择过程,这就涉及到了选择的策略问题,如何选择出集群中的一个实例呢?在SpringCloud中有一个有LoadBalancer和Ribbon帮我们完成这一选择过程。
LoadBalancer
LoadBalancer是SpringCloud自己实现的客户端负载均衡器。由于从Spring Cloud 2020.0.0 版本开始,Ribbon 正式进入维护模式,所以 Spring Cloud 逐步放弃Ribbon的使用,并且将 LoadBalancer 被推荐为主要的负载均衡解决方案,所以接下来我们在学习一下LoadBalancer。
基本使用
首先我们需要在项目中引入如下依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>接下来,我们就可以开始使用了
@Configuration
public class RestTemplateConfig {
@Bean
// 只需要加上该注解,即可完成LoadBalancer的整合
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
} // 查询订单数据
Order order = orderMapper.findById(orderId);
// 注意url中无需写ip:port,而变成了服务名称
String url = "http://user-service/user/address/{id}";
String address = restTemplate.getForObject(url, String.class, order.getUserId());
order.setAddress(address);
// 返回服务调用的结果
return order;我们发现,项目中整合了LoadBalancer之后,服务调用根据服务名称即可实现。
负载均衡策略
简单使用LoadBalancer之后,选择已经很好的实现了。同时,我们也会发现LoadBalancer默认实现的负载均衡策略是轮训策略(Round-Robin)。那么问题来了,LoadBalancer只能使用轮训策略吗? 当然不是,LoadBalancer本身还支持如下两种种常用的负载均衡策略:
| 策略 | 实现类 | 描述 |
|---|---|---|
| 轮训策略 | RoundRobinLoadBalancer | 轮训选择 |
| 随机策略 | RandomLoadBalancer | 随机选择 |
那么如何指定不同的负载均衡策略呢,通过配置类即可,可以分为两步:
第一步:定义所要使用的负载均衡类
public class CustomLoadBalancerConfiguration {
/*
environment:包含了一些配置信息
loadBalancerClientFactory:创建LoadBalancerClient对象的工厂
*/
@Bean
ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {
// 获取目标服务名称
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
// 创建用于获取目标服务实例列表的工厂对象
ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSuppliers
= loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class);
// 创建随机负载均衡策略
return new RandomLoadBalancer(serviceInstanceListSuppliers, name);
}
}第二步,通过@LoadBalancerClient注解使其生效,完成与RestTemplate的整合
@LoadBalancerClient(value = "user-service", configuration = CustomLoadBalancerConfiguration.class)
@Configuration
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}- LoadBalancerClient注解中的 value值表示负载均衡策略所针对的服务名称,因为我们可以对不同的服务配置不同的负载均衡策略
- configuration引入value所表示的服务的,所使用的负载均衡配置类
当然,上述的方式还可以使用另外一个注解完成,统一声明针对所有服务的负载均衡配置:
@LoadBalancerClients(
@LoadBalancerClient(value = "user-service", configuration = CustomLoadBalancerConfiguration.class)
)
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}当然,有的同学可能会问了,如果我想让针对所有服务的负载均衡都是用相同的负载均衡策略可以吗?当然可以
@LoadBalancerClients(
defaultConfiguration = CustomLoadBalancerConfiguration.class
)
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}LoadBalancer缓存
本来我们每次在调用一个服务的时候,LoadBalancer都应该通过注册中心的客户端,获取当前被调用服务的服务实例列表然后选择。但是,唯一一定程度提高效率,LoadBalancer的默认实现在有一个自己的缓存,用来缓存服务实例列表。关于这个缓存,在实际生产环境开启是可以提升效率的,但是在我们讲课的时候,为了测试方便,我们需要关闭它。
spring:
cloud:
loadbalancer:
cache:
enabled: false自定义负载均衡策略
当然,由于LoadBalancer本身提供的负载均衡策略比较少,所以实际开发中,有可能我们会根据需要自己实现自定义的负载均衡策略。
public class MyLoadBalancer implements ReactorServiceInstanceLoadBalancer {
// 服务名称
final String serviceId;
// 获取ServiceInstanceListSupplier对象的工厂
ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
public MyLoadBalancer(String serviceId, ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider) {
this.serviceId = serviceId;
this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider;
}
/*
我们需要实现该方法,实现自己的自定义负载均衡策略
*/
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
}
}public class MyLoadBalancer implements ReactorServiceInstanceLoadBalancer {
// 服务名称
final String serviceId;
// 获取ServiceInstanceListSupplier对象的工厂
ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
public MyLoadBalancer(String serviceId, ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider) {
this.serviceId = serviceId;
this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider;
}
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
// 得到获取服务实例列表的supplier对象
ServiceInstanceListSupplier serviceInstanceListSupplier = serviceInstanceListSupplierProvider.getIfAvailable(NoopServiceInstanceListSupplier::new);
//
return serviceInstanceListSupplier
// 获取目标服务实例列表
.get(request)
// 取出第一个列表(实际上)
.next()
// 将服务列表转化为一个服务实例(其实就是选择一个服务实例)
.map(serviceInstances -> doChooseSingleServer(serviceInstances));
}
/*
通过这个方法时实际完成服务实例的选择
*/
private Response<ServiceInstance> doChooseSingleServer(List<ServiceInstance> serviceInstances) {
// 选择策略简单粗暴,选择列表中的第一个服务实例
ServiceInstance serviceInstance = serviceInstances.get(0);
// 将选择结果封装到DefaultResponse中返回
return new DefaultResponse(serviceInstance);
}
}Ribbon负载均衡(知道)
Ribbon也是是一个客户端负载均衡器,能够给HTTP客户端带来灵活的控制。在SpringCloud2020之前的版本中默认使用的是Ribbon,所以我们也需要知道。它所支持的负载均衡策略如下:
| 策略 | 实现类 | 描述 |
|---|---|---|
| 随机策略 | RandomRule | 随机选择server |
| 轮训策略 | RoundRobinRule | 轮询选择 |
| 重试策略 | RetryRule | 对选定的负载均衡策略(轮训)之上的重试机制,在一个配置时间段内当选择服务不成功,则一直尝试使用该策略选择一个可用的服务; |
| 最低并发策略 | BestAvailableRule | 逐个考察服务,如果服务断路器打开,则忽略,再选择其中并发连接最低的服务 |
| 可用过滤策略 | AvailabilityFilteringRule | 过滤掉因一直失败并被标记为circuit tripped的服务,过滤掉那些高并发链接的服务(active connections超过配置的阈值) |
| 响应时间加权重策略 | WeightedResponseTimeRule | 根据server的响应时间分配权重,响应时间越长,权重越低,被选择到的概率也就越低。响应时间越短,权重越高,被选中的概率越高,这个策略很贴切,综合了各种因素,比如:网络,磁盘,io等,都直接影响响应时间 |
| 区域权重策略 | ZoneAvoidanceRule | 综合判断服务所在区域的性能,和服务的压力,轮询选择server并且判断一个AWS Zone的运行性能是否可用,剔除不可用的Zone中的所有server |
RestTemplate整合Ribbon
因为在SpringCloud2020之前,nacos客户端已经自己整合了ribbon依赖,所以实际上我们并不需要去添加该依赖就可以使用Ribbon了,仍然是使用@LoadBalance注解
@Configuration
public class ClientConfig {
@Bean
@LoadBalanced
public RestTemplate template() {
return new RestTemplate();
}
}然后在使用RestTemplate发起调用的时候,直接使用服务名进行调用即可
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.利用RestTemplate发起http请求,查询用户
// 2.1.url路径
String url = "http://user-service/user/address/{userId}";
// 2.2.发送http请求,实现远程调用
String userAddress = restTemplate.getForObject(url, String.class, order.getUserId());
// 3.封装user到Order
order.setAddress(userAddress);
// 4.返回
return order;指定Ribbon负载均衡策略
和Spring Cloud LoadBalancer的使用方式类似
- Ribbon也可以指定针对某个服务或所有服务使用的负载均衡策略
- 我们也可以实现Ribbon的自定义负载均衡策略
声明式接口调用
现在我们的服务调用过程,又变得简单了一些,因为Ribbon帮助我们解决了,服务调用过程中的选择问题。再来看一下我们的服务调用代码
// 2.1.url路径
String url = "http://user-service/user/address/{userId}";
// 2.2.发送http请求,实现远程调用
String userAddress = restTemplate.getForObject(url, String.class, order.getUserId());
我们觉得以上的代码还是不够简洁,如果我们希望对于服务(服务中的Controller方法)调用,就像对普通方法一样的简单?就类似下面的代码一样:
public interface RemoteUserService {
@GetMapping("/user/address/{id}")
public String queryById(@PathVariable("id") Long id);
}// 就像调用普通方法一样,调用到用户服务中的方法
String userAddress = remoteUserService.queryById(1);OpenFeign就可以帮助我们实现这样的功能,进一步简化服务调用的代码。
OpenFeign是一个实现Java代码和Http客户端绑定的绑定器,通俗的来解释,它可以帮助我们以统一的方式,将接口"翻译"成Restful风格的请求。
OpenFeign的使用
因为OpenFeign本身,充当着一个“翻译”的角色,可以将我们的Java接口翻译为对应的Http APIs,所以对于我们来说,OpenFeign也可以理解为一种服务调用的客户端,正因为是服务调用的客户端,所以只在服务消费者一端使用。
简单参数(返回值)
虽然,OpenFeign本身仅仅只是在客户端使用,但是因为使用了OpenFeign意味着服务的调用是面向Java接口的,而非HTTP API的,调用方式发生了改变。所以我们需要给order-service添加OpenFeign依赖
添加如下依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>定义用来调用用户服务的OpenFeign接口
// 接口需要加FeignClient指定该接口中的方法,所调用的目标服务
@FeignClient("user-service")
public interface UserFeignClient {
/* 接口方法上的注解以及方法参数主机,用来表示调用该方法时
所发起的http请求的pah路径,以及参数
*/
@GetMapping("user/address/{id}")
public String queryById(@PathVariable("id") Long id);
}在启动类上加注解@EnableFeignClients,才能让我们定义的FeignClient生效
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
@MapperScan("com.cskaoyan.order.mapper")
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}
以上的OpenFeign的依赖,接口定义,以及生效注解都准备好了,我们就可以开始使用OpenFeign了,在订单服务中,我们的服务调用代码可以修改如下:
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.利用OpenFeign接口发起http请求,查询用户
String userAddress = userFeignClient.queryById(order.getUserId());
// 3.封装user到Order
order.setAddress(userAddress);
// 4.返回
return order;注意事项
- OpenFeign接口中定义的方法名,不需要和被调用的,目标服务的Controller方法的方法名相同,只要请求的path部分以及参数对应即可
- 如果需要传递请求参数,比如http://ip:port/path?arg1=value1&arg1=value2,此时我们需要给OpenFeign接口的方法参数加上@RequestParam注解
@FeignClient("test-service")
public interface TestArgFeignClient {
@GetMapping("test/arg")
public String testOpenFeignArg(@RequestParam("arg1") Long arg1,
@RequestParam("arg2") Long arg2);
}对象参数(返回值)
刚才我们测试了,简单参数(Jdk中本身就有的数据类型),现在我们来看看另一种情况,当我们被调用的目标服务方法需要返回(或接收)一个自定义对象User的时候,实现如下:
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
/**
* @param id 用户id
* @return 用户
*/
@GetMapping("/address/{id}")
public User queryObjectById(@PathVariable("id") Long id) {
// 根据id查询用户的地址信息
return userService.queryObjectById(id);
}
}此时,在订单服务中,我们的OpenFeign接口方法也就要做出相应的改变
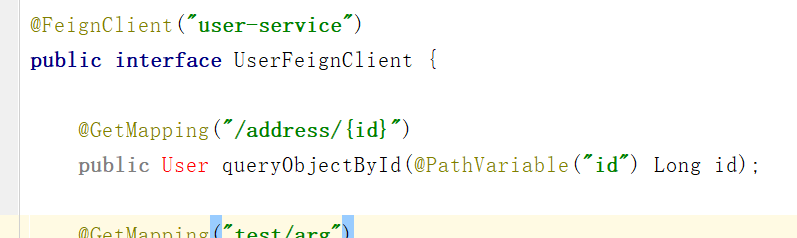
@FeignClient("user-service")
public interface UserFeignClient {
@GetMapping("user/address/{id}")
public User queryObjectById(@PathVariable("id") Long id);
}但是,真的这么简单就可以了吗?当然不是
我们很明显的看到报错了,原因是Order-Service和User-Service是两个独立的Maven工程,因此Order-Service并不认识在User-Service中定义的User类,那怎么解决这个问题呢?
- 让Order-Service也认识User-Service中定义的即可
- 因此我们在添加一个Maven工程,在该工程中,定义User,在让Order-Service和User-Service都依赖这个Maven工程即可
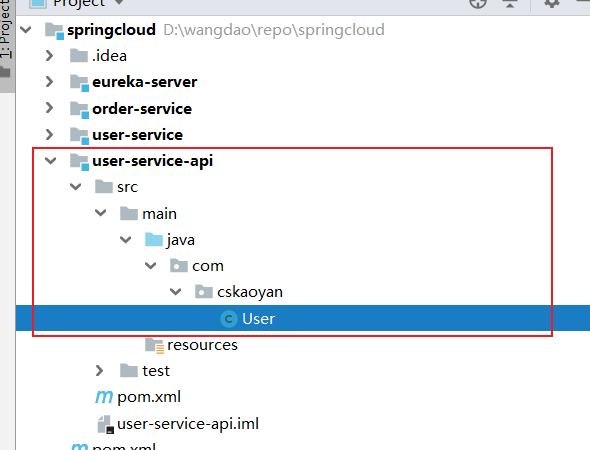
同时,分别在Order-Service和UserService中添加User-service-api的依赖即可
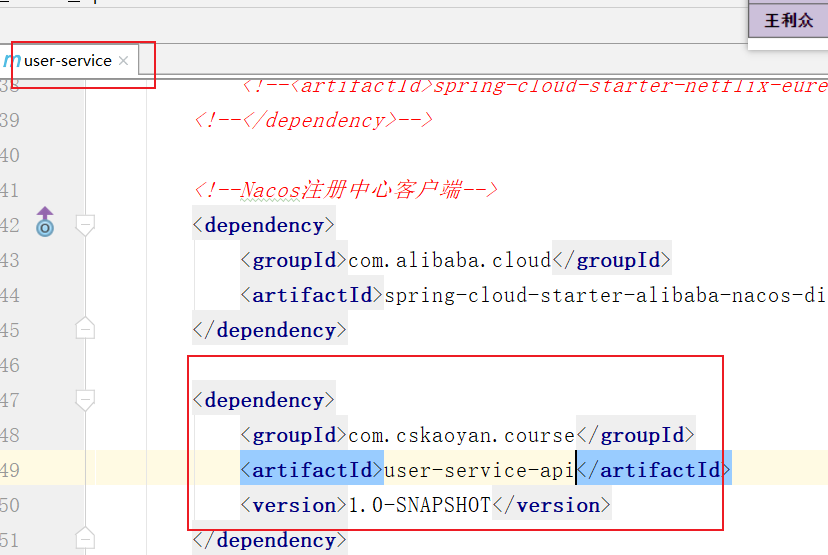
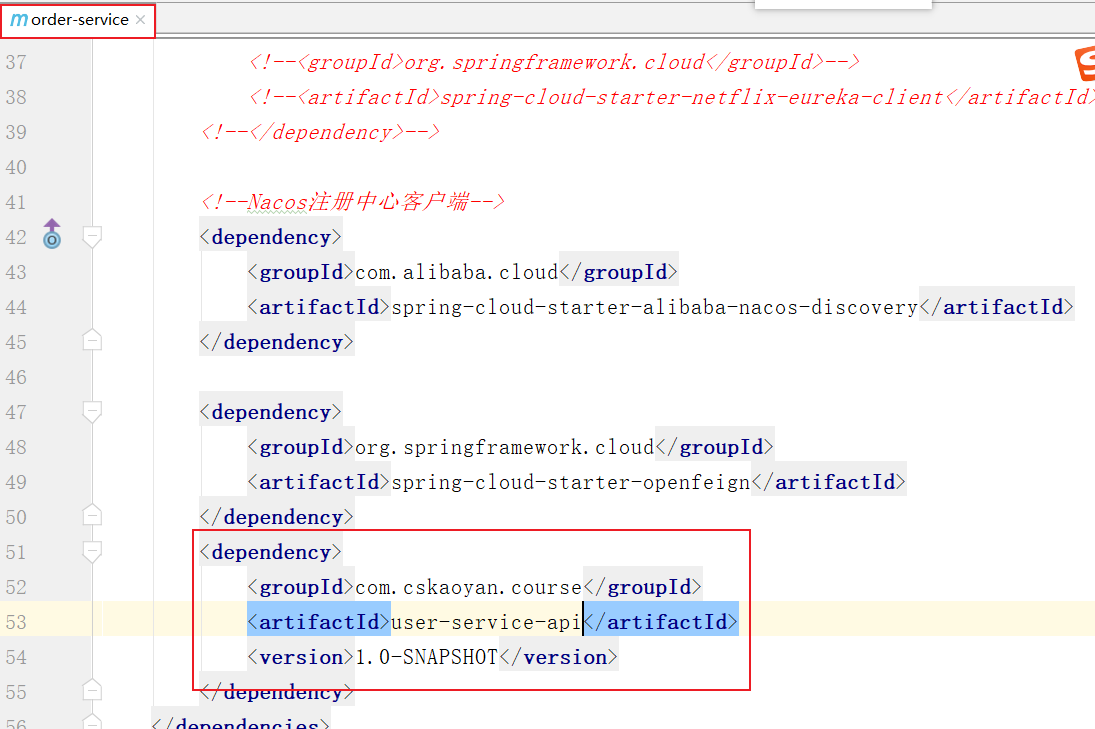
这里要注意,为什么我们不直接让Order-Service直接依赖UserService,这样不是也可以让Order-Service认识在User-Service中定义的User类吗?
- 因为一旦Order-Service依赖了User-Service那么OrderService在打包的时候,就会把User-Service的代码直接打包在一起
- 两个服务打成一个jar包,一旦运行起来,两个服务的代码运行在同一个进程中,这违反了微服务的理念
FeignClient日志输出
当我们调用FeignClient发出请求的时候,如果我们希望能看到其发出的具体Http请求,我们可以通过配置来实现。
# 这里的xxx表示我们自己的定义的FeignClient所在包的包名(比如: com.cskaoyan.feign.consumer.api)
logging:
level:
xxx: debug定义配置类,在配置类中,配置Feign的日志输出级别
@Configuration
public class FeignConfig {
@Bean
public Logger.Level logLevel() {
return Logger.Level.FULL;
}
}这样当我们,通过在对应的FeignClient对象上,调动方法,发起http请求的时候,对应的请求就会打印在控制体

服务调用的超时设置
通常,一次远程调用过程中,服务消费者不可能无限制的等待服务提供者返回的结果,正常情况下,服务提供者的一次调用执行过程也不会执行很长时间(除非出现网络故障,或者服务提供者宕机等问题),所以为防止,在非正常情况下服务消费者在调用过程中的长时间阻塞等待,对于一次服务调用过程,我们会设置其超时时间。一次服务调用,超时未返回即认为调用失败。在使用Feign的时候,我们可以配置其超时时间。默认超时时间是60s
feign:
client:
config:
# default表示设置对所有服务设置调用超时时间的,如果想要设置某个服务的,将default改为对应服务名即可
default:
connectTimeout: 5000 # 连接超时时间
readTimeout: 5000 # 调用超时时间问题引出
设想一下,如果每个服务都有自己的配置,比如服务访问的数据库地址等,但是某一天,数据库部署的服务器地址变了,此时会发生什么呢?为了让服务能够正确访问到数据库,我们得停止每一个服务,重新修改每一个服务的配置文件,然后在重新启动每个服务,在这个过程中就会出现两个问题:
- 修改配置文件的工作繁琐,工作量大,尤其当服务数量较多的时候
- 要让新的配置生效,得重启服务
配置中心
如果要解决以上问题,那么在我们微服务架构的项目中,我们就得引入一个新的角色——配置中心来解决这个问题了,类似于注册中心,配置中心的实现也有多种,而Nacos同时也实现了配置中心的角色。
- 使用配置中心可以让您以中心化、外部化和动态化(动态化即可以实时刷新配置)的方式管理所有环境的应用配置和服务配置。
- 动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。
Nacos 配置中心
Nacos除了可以作为服务注册中心之外,还可以实现服务配置中心的功能。
在使用Nacos配置中心之前,我们必须对于注册中心的配置信息有一个清楚的认识:
- 配置中心中的配置,主要是以键值对的形式存在的,即每条配置都以key-value的形式存储,key是配置的名称,value才是配置的值
- 所以,很明显,不同配置的key值应该有所区别,或者即使key值相同,我们也应该有办法区分他们,即给key值划分不同的维度。
所以接下来,我们得介绍一下Nacos中定义的基本概念:
- 配置项: 一个具体的可配置的参数与其值域,通常以 param-key=param-value 的形式存在。例如我们常配置系统的日志输出级别(logLevel=INFO|WARN|ERROR) 就是一个配置项。
- 配置集:一组相关或者不相关的配置项的集合称为配置集。在系统中,一个配置文件通常就是一个配置集,包含了系统各个方面的配置,每一个配置集都对应一个唯一的DataId,DataId必须由我们自己定义。
- 配置分组: Nacos 中的一组配置集,是组织配置的维度之一,每一个分组都有一个唯一的组名,如果我们未定义,则默认使用DEFAULT-GROUP分组
- 命名空间: 用于进行用户粒度的配置隔离,每一个命名空间都有一个唯一的Id值,如果我们未定义,则默认使用public命名空间
以上几个概念其实就是在告诉我们区分不同配置项的维度,Nacos提供多个维度帮助我们区分不同的配置,它们的关系如下图所示
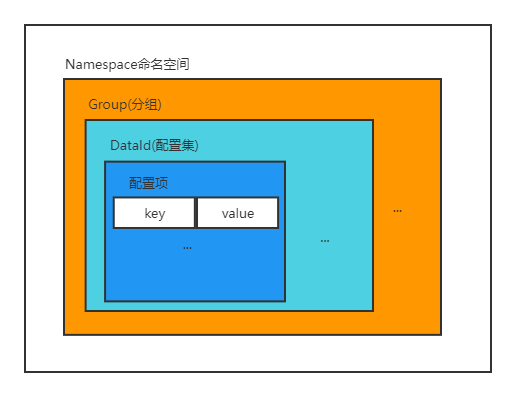
有了以上不同的配置项的划分维度,我们就可以灵活定义我们的配置项了。其中
- 配置项中的key值,以及配置分组的组名都由我们自己根据场景去定义
- 命名空间的Id值,在我们定义命名空间的时候,由Nacos帮我们生成
Nacos配置中心的使用
服务配置
在用户服务中添加如下,访问nacos配置中心的依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>每个服务都可以在配置中心中管理每个服务自己的配置(Profile配置)。可以指定每个服务所要读取的配置集名称
spring:
cloud:
nacos:
config:
# 配置中心地址
server-addr: 192.168.153.130:8848
# 配置集的文件格式
file-extension: yml
config:
import:
- nacos:配置集名称
- nacos:配置集名称?group=MY_GROUP # 覆盖默认上面的group, 读取MY_GROUP的配置集 虽然这里的配置集id的定义可以是任意字符串,但是推荐大家使用如下公式生成目标配置集id即dataId
${spring.application.name}-${spring.profiles.active}.ymlspring.profiles.active即为当前环境对应的 profile- 最后的yml在说明配置文件的格式
这样一来,类比于上一个阶段我们在项目中通过修改spring.profiles.active配置值,我们就可以在配置中心实现多环境配置了。当然,除此之外,我们还可以通过制定namespace和group实现环境配置
spring:
application:
name: xxx
profiles:
active: dev
cloud:
nacos:
config:
#namespace: xxx
#group: xxx
server-addr: 127.0.0.1:8848
file-extension: yml
config:
import:
- nacos:配置集名称
- nacos:配置集名称?group=MY_GROUP # 覆盖默认上面的group, 读取MY_GROUP的配置集在nacos-config的目录下添加application.yml,在application.yml配置文件中的配置如下
# 项目中的其他配置都包含在application.yml文件中
server:
port: 3377
spring:
application:
name: nacos-config-client
profiles:
active: dev # 表示开发环境
cloud:
nacos:
config:
#Nacos作为配置中心地址
server-addr: localhost:8848
#指定yaml格式的配置,如果是yml文件
file-extension: yml
# 指定配置所属的配置分组
# group: DEV_GROUP
# 指定配置所属的命名空间
# namespace: 7d8f0f5a-6a53-4785-9686-dd460158e5d4
config:
import:
- nacos:配置集名称
- nacos:配置集名称?group=MY_GROUP # 覆盖默认上面的group, 读取MY_GROUP的配置集测试代码如下:
@RestController
public class ConfigController {
@Value("${nacos.config}")
String config;
@GetMapping("/nacos/config")
public String nacosCofnig() {
return config;
}
}服务配置的动态刷新
配置存储在配置中心之后,如果配置值发生了改变,是否必须重启服务才能让配置生效呢?当然不是,基于Nacos配置中心,我们可以实现配置的动态刷新。只需在需要使用配置值的类上加上@RefreshScope注解即可
@RestController
// 在使用配置的类上加该注解才能实现配置的动态刷新
@RefreshScope
public class UserController {
@Value("${nacos.config}")
String config;
@GetMapping("/nacos/config")
public String nacosCofnig() {
return config;
}
}注意:
- 配置中心的配置优先级高于本地配置
Nacos 配置的持久化
我们在Nacos服务器上写入的配置,会被持久化保存到Nacos自带的一个嵌入式数据库derby中,因此当我们重启Nacos之后,仍然可以看到之前的配置信息。但是,使用嵌入式数据库实现数据的存储,不方便观察数据存储的基本情况,因此,Nacos还支持将配置信息写入Mysql中:
- 在数据库中,创建名为nacos的数据库
- 在nacos数据库中,执行数据库初始化文件:nacos-mysql.sql(改文件在conf目录下已经提供)
- .修改conf/application.properties文件,增加支持mysql数据源配置(目前只支持mysql),添加mysql数据源的url、用户名和密码。
spring.datasource.platform=mysql
db.num=1
# 这里的url要改成你自己的mysql数据库地址,并在你的mysql中创建名为nacos的数据库
db.url.0=jdbc:mysql://11.162.196.16:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
# 这里要改成你自己登录mysql的用户名和密码
db.user.0=nacos_devtest
db.password.0=youdontknow在配置了mysql数据库之后,我们会发现,之前配置中心的配置信息全部消失了,那是因为我们之前使用的是nacos的内嵌数据库derby,现在切换到mysql之后数据存储在nacos这个数据库中,而该数据库现在是没有数据的。
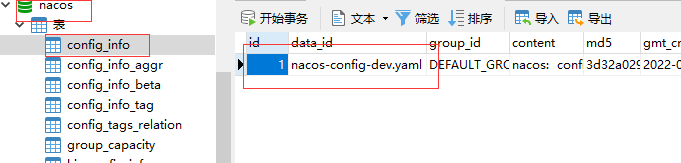
但是当我们,在nacos的控制台重新添加配置数据之后,我们就可以在mysql中看到了
网关介绍
如果没有网关,难道不行吗?功能上是可以的,我们直接调用提供的接口就可以了。那为什么还需要网关?
因为网关的作用不仅仅是转发请求而已。我们可以试想一下,如果需要做一个请求认证功能,我们可以接入到 API 服务中。但是倘若后续又有服务需要接入,我们又需要重复接入。这样我们不 仅代码要重复编写,而且后期也不利于维护。
由于接入网关后,网关将转发请求。所以在这一层做请求认证,天然合适。这样这需要编写一次代码,在这一层过滤完毕,再转发给下面的 API。
所以 API 网关的通常作用是完成一些通用的功能,如请求认证,请求记录,请求限流,黑白名单判断等。
API网关是一个服务器,是系统的唯一入口。 API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关提供REST/HTTP的访问API。
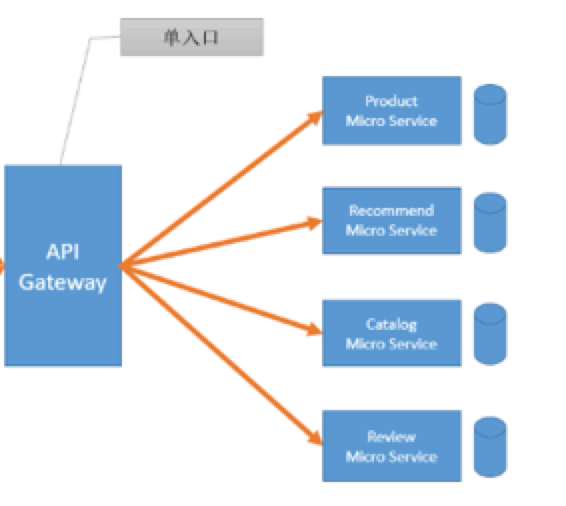
多入口:
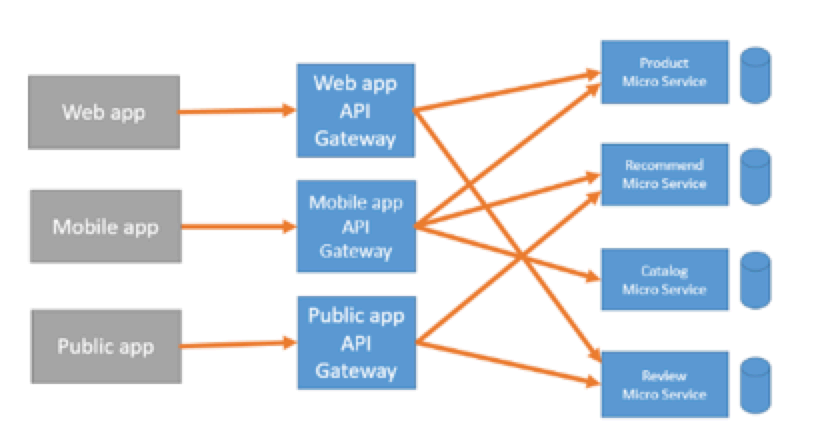
网关使用
Spring Cloud Gateway是一个基于Spring生态的API网关,基于WebFlux框架实现。它旨在以简单高效的方式实现,请求路由,以及一些其他的边缘功能,比如,安全,监控等功能。
通用的网关框架除了Gateway之外,还有Zuul,Zuul2等框架。其中,Zuul是由Netflix公司开发出的最早的通用网关框架,功能丰富,但是基于同步阻塞式Servlet API实现,性能不佳。Zuul2可以理解为Zuul的升级版,它基于异步非阻塞模式实现,但是由于zuul2在开发过程中一直延期,所以Spring Coud官方并未采用Zuul2最为自己的通用网关,而是自己推出了自己的基于异步非阻塞实现的第二代服务网关Gateway。
核心概念
- Predicate:表示路由规则的匹配条件
- Filter:过滤器,在请求处理之前(Pre)实现队请求的拦截处理,在请求处理之后(Post)实现对响应的拦截处理
- Route:定义请求和路由目标之间的映射,它由一个唯一ID(自定义),一个目标地址URI,表示路由条件Predicate集合,以及一个Filter集合组成。对于一个请求而言,如果它满足一个路由的全部路由条件(Predicate),那么该请求就会按照该路由(Route)规则,向目标地址URI转发。
spring:
cloud:
gateway:
#定义多个路由
routes:
# 一个路由route的id
- id: test_route
# 该路由转发的目标URI
uri: https://example.org
# 路由条件集合
# /red/aaa
predicates:
- Path=/red/**
# 过滤器集合
filters:
- AddRequestParameter=color, red我们再来看一看Gateway是如何工作的
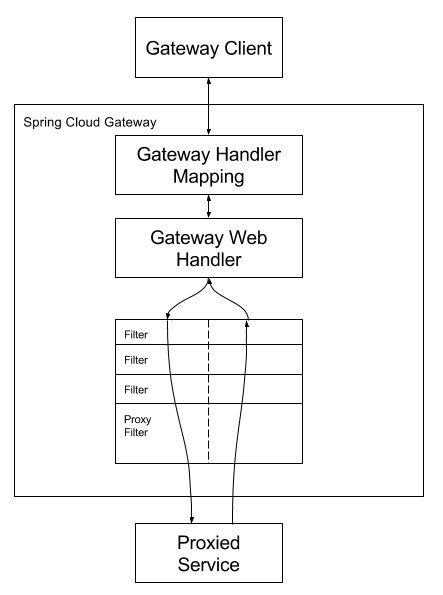
- 客户端向Gateway发起请求
- Gateway的Handler Mapping组件,会对请求做路由匹配,如果请求和某个路由规则匹配,则把该请求交给Web Handler处理
- 在将请求转发给目标之前,Web Handler会将请求,交给满足请求过滤条件的一系列过滤器,即一个过滤器链对该请求进行过滤处理
- 过滤器链,被虚线分隔,是因为过滤器既可以在转发请求前拦截请求,也可以在请求处理之后对响应进行拦截处理。
网关路由配置
SpringCloud Gateway的网关配置有两种方式,配置文件配置和代码配置两种方式。
在使用Gateway之前,我们得单独创建一个Maven工程,引入Gateway依赖,之后将其独立启动。需要的依赖如下
<dependencies>
<!--gateway-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--loadbalancer依赖-->
</dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-loadbalancer</artifactId>
</dependency>
<!--单元测试依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>配置文件配置
假设现在我们在基于Gateway的网关中,添加路由配置,实现如下功能:
- 将URI匹配/routeconfig/rest/**的请求,转发给某一个服务或应用(将请求路由到服务或应用)
- 将URI匹配/guonei/**的请求,转发给另一个服务或应用(将请求路由到服务或应用)
spring:
application:
name: cloud-gateway
cloud:
gateway:
routes:
#路由的ID,没有固定规则但要求唯一,建议配合服务名
- id: config_route
#匹配后提供服务的路由地址
uri: http://localhost:8002
# 断言,路径相匹配的条件
predicates:
- Path=/routeconfig/rest/**
#路由的ID,没有固定规则但要求唯一,建议配合服务名
- id: config_news
#匹配后提供服务的路由地址
uri: http://news.baidu.com
# 断言,路径相匹配的进行路由
predicates:
- Path=/guonei/** 代码配置
@Configuration
public class GateWayConfig
{
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder routeLocatorBuilder)
{
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
// route方法的第一个参数表示新建的routeID
// 第二个参数表示Route对象对应的的Builder对象
routes.route("code_route_config",
r -> r.path("/guonei")
.uri("http://news.baidu.com")).build();
return routes.build();
}
}动态路由
网关接收外部请求,按照一定的规则,将请求转发给其他服务或者应用。如果站在服务调用的角度,网关就扮演着服务消费者的角色,此时,如果我们再来看看服务调用的目标URI配置,就会很自然的发现一个问题,服务提供者调用的地址是写死的,即网关没有动态的发现服务,这就有涉及到了我们之前解决过的服务的自动发现问题,以及发现服务后,所涉及到的服务调用的负载均衡的问题。
回忆一下,我们之前是如何解决这些问题的?通过Nacos或者Eureka注册中心动态发现服务,通过Ribbon进行服务调用的负载均衡。同样,Gateway也可以整合Nacos或者Eureka,Ribbon或LoadBalancer从而实现,动态路由的功能。
想要使用动态路由的功能,首先我们要整合注册中心,这里我们以Nacos为例
<!--SpringCloud ailibaba nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>然后在配置文件中,添加注册中心的配置
spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848还要修改路由配置,使用动态路由
spring:
application:
name: cloud-gateway
cloud:
nacos:
discovery:
server-addr: localhost:8848
gateway:
routes:
#路由的ID,没有固定规则但要求唯一,建议配合服务名
- id: config_route
#匹配后提供服务的路由地址, 这里lb之后,跟的是要调用的服务名称
uri: lb://nacos-provider-8002
# 断言,路径相匹配的条件
predicates:
- Path=/routeconfig/rest/** 此时,当id为config_route的路由规则匹配某个请求后,在调用该请求对应的服务时,就会从nacos注册中心自动发现服务,并在服务调用的时候实现负载均衡。
Predicate
在Gateway中,有一些的内置Predicate Factory,有了这些Pridicate Factory,在运行时,Gateway会自动根据需要创建其对应的Predicate对象测试路由条件。具体的有兴趣的话大家可以去查看官网: https://spring.io/projects/spring-cloud-gateway
- Path 路由断言 Factory: 根据请求路径匹配的路由条件工厂
spring:
cloud:
gateway:
routes:
- id: path_route
uri: https://example.org
predicates:
# 如果可以匹配的PathPattern有多个,则每个路径模式以,分开
- Path=/red/{segment},/blue/{segment}- After 路由断言 Factory:在指定日期时间之后发生的请求都将被匹配
spring:
cloud:
gateway:
routes:
- id: after_route
uri: http://example.org
predicates:
- After=2017-01-20T17:42:47.789-07:00[America/Denver]- Cookie 路由断言 Factory
Cookie 路由断言 Factory有两个参数,cookie名称和正则表达式。请求包含次cookie名称且正则表达式为真的将会被匹配。
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: http://example.org
predicates:
- Cookie=chocolate, ch.p- Header 路由断言 Factory
Header 路由断言 Factory有两个参数,header名称和正则表达式。请求包含次header名称且正则表达式为真的将会被匹配。
spring:
cloud:
gateway:
routes:
- id: header_route
uri: http://example.org
predicates:
- Header=X-Request-Id, \d+- Host 路由断言 Factory
Host 路由断言 Factory包括一个参数:host name列表。使用Ant路径匹配规则,.作为分隔符。
spring:
cloud:
gateway:
routes:
- id: host_route
uri: http://example.org
predicates:
- Host=**.somehost.org,**.anotherhost.org- Method 路由断言 Factory
Method 路由断言 Factory只包含一个参数: 需要匹配的HTTP请求方式
spring:
cloud:
gateway:
routes:
- id: method_route
uri: http://example.org
predicates:
- Method=GET所有GET请求都将被路由
Filter
Gateway内置了很多的Filter这里就不再一一列举了。我们重点来学习下自定义Filter。
@Component
public class MyGatewayFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
MultiValueMap<String, HttpCookie> cookies = request.getCookies();
List<HttpCookie> tokens = cookies.get("access_token");
if (tokens == null || tokens.size() == 0) {
throw new RuntimeException("少了cookie!");
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 0;
}
}